

Predictive modeling is a method of predicting future outcomes by using data modeling. It’s one of the premier ways a business can project a path forward and make plans accordingly. While not foolproof, organizations commonly rely upon this method due to a history of high accuracy rates.
What Is Predictive Modeling?
Predictive modeling is a statistical technique using machine learning (ML) and data mining to predict and forecast likely future outcomes with the aid of historical and existing data. The process works by analyzing current and historical data to project what it learns on a model generated for a forecast of likely outcomes. Predictive modeling can predict just about anything, from TV ratings and a customer’s next purchase to credit risks and corporate earnings.
A predictive model is not fixed; it is validated or revised regularly to incorporate changes in the underlying data. In other words, it’s not a one-and-done prediction. Predictive models make assumptions based on what has happened in the past and what is happening now. New incoming data can show current shifts and trends, and the impact on the likely future outcome requires further recalculation. For example, a software company could model historical sales data against marketing expenditures across multiple regions to create a model for future revenue based on the impact of the marketing spend.
Most predictive models work fast and often complete their calculations in real time. For example, banks and retailers can calculate the risk of an online mortgage or credit card application and accept or decline the request almost instantly based on that prediction.
Some predictive models are more complex, such as those used in computational biology and quantum computing; the resulting outputs take longer to compute than a credit card application but are still faster than previous methods thanks to advances in technological capabilities, including computing power.
Key Takeaways
- Predictive models analyze historical and current data to forecast future outcomes, informing decisions about operations, resources, and strategy.
- Predictive models empower businesses to recognize opportunities, reduce risks, and optimize resources, especially when paired with ongoing data management, testing, and maintenance practices.
- Predictive modeling’s adaptable framework can be customized to address specific challenges across diverse industries and applications.
- Therefore, businesses should carefully choose the right models and tools that will address their specific needs.
Top 5 Types of Predictive Models
Fortunately, predictive models don’t have to be created from scratch for every application. Predictive modeling tools use a variety of vetted models and algorithms applicable to a wide spread of use cases.
Predictive modeling techniques have improved over time. Elements such as greater data volume, greater compute power, AI and ML capabilities, and analytics advancements continue to push what models can achieve.
The following describe five of the most commonly used predictive models:
- Classification model: Considered the simplest model, it categorizes data for simple and direct query response. An example use case is an application processing financial data to answer “is this a fraudulent transaction?”
- Clustering model: This model nests data together by common attributes. It works by grouping things or people with shared characteristics or behaviors and plans strategies for each group at a larger scale. An example is determining credit risk for a loan applicant based on what other people in similar situations did in the past.
- Forecast model: Forecast models are quite popular and work on anything with a numerical value based on learning from historical data. For example, to determine a restaurant’s weekly lettuce order or a customer support agent’s daily call volume, the system looks back to historical data.
- Outliers model: This model works by analyzing abnormal or outlying data points. For example, a bank might use an outlier model to identify fraud by asking whether a transaction is outside of the customer’s normal buying habits or whether an expense in a given category is normal or not. In this situation, a $1,000 credit card charge for a washer and dryer in the cardholder’s preferred big box store would not be alarming, but $1,000 spent on designer clothing in a location where the customer has never charged other items might be indicative of a breached account.
- Time series model: This model evaluates a sequence of data points based on time. For example, the number of stroke patients admitted to the hospital in the last four months is used to predict how many patients the hospital might expect to admit next week, next month, or the rest of the year. A single metric measured and compared over time is thus more meaningful than a simple average.
Common Predictive Algorithms
Predictive algorithms use one of two things: ML or deep learning. Both are subsets of artificial intelligence (AI) and deep learning is a subset in itself of ML. ML refers to systems that learn as they consume data, whether through intended purposes or specific training datasets. Deep learning is capable of more complex learning through the use of neural networks, which mimic the way the human brain connects information nodes. Deep learning models often stack layers of neural networks to build complex “thoughts” as outputs pass from layer to layer. These stacks are often referred to as “hidden layers,” as they sit collectively between input and output.
Besides neural networks, some of the more common predictive algorithms are:
- Random Forest: This algorithm combines decision trees, none of which are related, and can use both classification and regression to classify vast amounts of data.
- Generalized Linear Model (GLM) for Two Values: This algorithm narrows down the list of variables to find “best fit.” It can work out tipping points and change data capture and other influences, such as categorical predictors(opens in a new tab), to determine the “best fit” outcome, thereby overcoming drawbacks in other models, such as a regular linear regression.
- Gradient Boosted Model: This algorithm also uses several combined decision trees, but unlike Random Forest, the trees are related. It builds out one tree at a time, thus enabling the next tree to correct flaws in the previous tree. It’s often used in rankings, such as on search engine outputs.
- K-Means: A popular and fast algorithm, K-Means groups data points by similarities and thus is often used for the clustering model. For example, a retailer can use K-Means to quickly render personalized retail offers to individuals within a huge group, such as a million or more customers with a similar liking of lined red wool coats.
- Prophet: This algorithm is used in time-series or forecast models for capacity planning, such as for inventory needs, sales quotas and resource allocations. It is highly flexible and can easily accommodate heuristics and an array of useful assumptions.
Predictive Modeling vs. Predictive Analytics
While often used interchangeably, predictive modeling and predictive analytics serve different but overlapping functions in data analysis. Predictive analytics is a broad discipline that encompasses the entire process of forecasting future events, including collecting and preparing data, analyzing statistics, and applying various forecasting techniques. Predictive analytics also involves selecting appropriate analytical approaches, interpreting results, and translating findings into actionable insights and strategies. For instance, a retail company’s predictive analytics approach would include collecting customer data, analyzing shopping patterns, and forecasting future behaviors. The company can use these predictions to develop targeted marketing strategies.
Predictive modeling, on the other hand, is focused specifically on creating statistical models that identify patterns and relationships to determine the likelihood of specific outcomes. While predictive analytics often uses multiple approaches to provide an overall strategic framework, predictive modeling represents the technical side of the equation, supplying the mathematical framework and tools required to make specific forecasts. In short, predictive analytics is the application of predictive modeling for business purposes. The aforementioned retail company, for example, might employ a specific predictive model that analyzes past customer purchase data to calculate the probability of a customer buying a particular product.
Benefits of Predictive Modeling
Predictive modeling helps leaders and managers make both wide-reaching and targeted data-driven decisions, while reducing the time, effort, and costs required to do so. The following describe five of the most common benefits produced by predictive modeling:
- Accuracy: By analyzing vast amounts of a business’s historical and current data, predictive modeling enhances forecast precision, allowing decision-makers to better anticipate market changes, customer behaviors, and potential risks.
- Decision-making: Predictive modeling helps leaders gain a deeper understanding of potential outcomes before making decisions. These models provide objective analyses that validate or challenge assumptions, leading to more competitive strategic planning that is also better aligned with realistic business conditions.
- Risk management: Through proactive risk identification, businesses can develop mitigation strategies to minimize impact on operations and revenue. Predictive modeling allows companies to better manage ongoing risks by assessing various risk factors simultaneously, from market volatility to operational challenges.
- Resource optimization: Companies can use predictive modeling tools for more efficient resource allocation, identifying potential bottlenecks and waste. Managers can then implement these allocation strategies across diverse resource needs, including inventory, workforce, and equipment maintenance.
- Profit margins: By prioritizing the above processes, businesses can improve workflows across their organization, significantly enhancing their profit margins and revenue. More precise predictions can lead to leaner production schedules, less waste, improved inventory management, and more effective marketing strategies.
Challenges of Predictive Modeling
It’s essential to keep predictive modeling focused on producing useful business insights because this technology can produce inaccurate, problematic, or valueless outputs. Some mined information is of value only in satisfying a curious mind and has few or no business implications. Getting side-tracked is a distraction few businesses can afford.
Also, being able to use more data in predictive modeling is an advantage only to a point. Too much data can skew the calculation and lead to a meaningless or an erroneous outcome. For example, more coats are sold as the outside temperature drops – but only to a point. People do not buy more coats when it’s -20 degrees Fahrenheit outside than when it’s -5 degrees. At a certain point, the weather is simply cold enough to spur the purchase of coats and more frigid temps no longer appreciably change that pattern.
In addition, because predictive modeling involves massive volumes of data, maintaining security and privacy will also be a challenge. Further challenges rest in machine learning’s limitations.
Limitations of Predictive Modeling
According to a McKinsey report(opens in a new tab), predictive modeling faces a range of standard limitations, coupled with their “best fixes.” The following details the most common of these limitation/fix combinations:
- Errors in data labeling: Reinforcement learning or generative adversarial networks (GANs) can help organizations overcome these types of errors.
- Shortage of massive data sets needed to train machine learning: A possible fix is “one-shot learning,” wherein a machine learns from a small number of demonstrations rather than on a massive data set.
- The machine’s inability to explain what and why it did what it did: Machines do not “think” or “learn” like humans. Likewise, their computations can be so exceptionally complex that humans have trouble finding, let alone following, the logic. All this makes it difficult for a machine to explain its work, or for humans to do so. Yet model transparency is necessary for a number of reasons, with human safety chief among them. Promising potential fixes include local-interpretable-model-agnostic explanations (LIME(opens in a new tab)) and attention techniques.
- Generalizability of learning, or rather lack thereof: Unlike humans, machines have difficulty carrying what they’ve learned forward. In other words, they have trouble applying what they’ve learned to a new set of circumstances. Whatever it has learned is applicable to one use case only. This is largely why we need not worry about the rise of AI overlords anytime soon. To enable reusability for predictive modeling—that is, useful in more than one use case—a possible fix is transfer learning(opens in a new tab).
- Bias in data and algorithms: Non-representation can skew outcomes and lead to risky, potentially harmful decisions. Further, baked-in biases are difficult to find and purge later. In other words, biases tend to self-perpetuate. This is a moving target, and organizations typically rely on bias detection tools and techniques to evaluate outputs, particularly during training.
Predictive Modeling Use Cases and Examples
While specifics vary from industry to industry, the fundamental idea behind implementing predictive models remains consistent: to turn past and present data into future-facing outcomes as a means to guide strategic planning. The following five specific use cases showcase a range of predictive modeling applications:
Finance
Financial institutions use predictive modeling to assess credit risk, detect fraud, and allocate funds. Companies use these models when making investments to forecast market trends, evaluate opportunities, and manage portfolio risk across assets. In banking, these models analyze historical transaction data and customer behavior patterns to identify suspicious activities and prevent fraudulent transactions in real time. For example, it may not be out of the ordinary for a frequent traveler to buy expensive airline tickets, but an atypical purchase of high-end clothing could be flagged and require validation before approval.
Utilities
Utility companies use predictive modeling to forecast energy demand, allocate resources, and plan infrastructure maintenance. By assessing weather patterns, historical usage records, and population growth trends, these tools allow providers to better predict peak demand periods and adjust supply and equipment use accordingly. These models also identify potential equipment failures before they occur, helping repair teams prioritize tasks and schedule proactive maintenance to prevent downtime and service interruptions.
Healthcare
Healthcare providers use predictive modeling to improve patient outcomes and reduce operational costs. At an individual level, models comb through patient data to identify high risks for specific conditions, enabling early intervention and preventive care. Hospitals can also use these tools to forecast patient admission rates and community health needs, allocating staff and medical supplies across multiple facilities accordingly, especially during large-scale outbreaks or health crises.
Retail
Retailers leverage predictive modeling to optimize inventory levels, personalize customer experiences, and predict future sales and revenue patterns. These models analyze purchasing behavior, seasonal trends, and external market factors to predict demand for specific products, store locations, and time periods. Advanced systems can even predict individual customer preferences and likely purchase decisions, powering targeted marketing campaigns and personalized bundles and promotions that increase order scope and frequency.
Supply Chain
For businesses navigating complex supply chains, predictive models anticipate potential disruptions, allowing managers to mitigate risks by strengthening logistics processes and proactively adjusting inventory levels. These models look at data, such as supplier performance, transportation routes, and market conditions, to identify potential bottlenecks or delays before they impact operations. Companies can also use predictive modeling to make internal improvements, such as optimizing warehouse space, planning equipment maintenance, reducing transportation costs, and maintaining optimal inventory levels companywide.
Predictive Modeling Best Practices
To be successful, predictive modeling requires careful planning, ongoing maintenance, and clear alignment with the company’s overall goals. The following best practices can help businesses maximize their return on investment and avoid common pitfalls:
- Start with clear business objectives: Clearly define the company’s specific challenges and how predictive modeling can overcome them. This early-planning stage helps establish realistic and measurable expectations and creates a road map for implementation teams.
- Ensure data quality and accessibility: Without high quality, clean data, models are more likely to make inaccurate or misleading predictions. By establishing robust data collection processes and regular data cleaning procedures, businesses can build a secure data infrastructure capable of handling the volume and variety of data needed for effective predictive modeling.
- Choose the right model type: Select modeling techniques and software that align with the business’s specific use cases, available data, and budget constraints. Companies should consider factors such as data volume, prediction speed requirements, model complexity, and desired outcomes.
- Validate and test thoroughly: regularly test models with diverse historical data and new scenarios. Through comprehensive testing, businesses can maintain prediction accuracy as new techniques and technology become available. These tests typically include systematic validation processes that check for bias, test model assumptions, and compare predicted versus actual outcomes.
- Monitor and update regularly: Plan periodic review cycles to assess model performance and update models with new data to maintain accuracy as markets, customer behaviors, and business conditions evolve. Many modern model providers, such as those that integrate features into their cloud-based enterprise resource planning (ERP) systems, update their systems regularly, minimizing the IT burden on their customers.
- Build cross-functional teams: Combine technical expertise with institutional knowledge by creating teams that include data scientists, stakeholders, subject-matter experts, and internal managers and analysts. Such collaboration can help make sure that models are technically sound and capable of addressing the business’s needs.
- Plan for scale: Consider any potential modeling tool’s ability to handle growing data volumes and increasing complexity as the business grows. These considerations include processing power, storage requirements, and integration capabilities with existing systems.
- Maintain documentation and governance: Document model development, assumptions, and validation processes throughout implementation and beyond. Clear governance procedures for model updates, access controls, and compliance with relevant regulations help staff get the most out of these tools and create consistency across the organization.
The Future of Predictive Modeling
Predictive modeling continues to evolve, driven by advances in ML, compute power, and data collection capabilities. While this technology is already bringing value across industries, emerging developments in AI, neural networks, large language models, and real-time analytics will likely lead to even more sophisticated and accessible modeling capabilities. In addition, businesses investing in this technology are realizing the competitive advantages of early adoption and proactively improving their operations, rather than struggling to adapt as these tools become more widespread.
By starting with established use cases and models that fit with their current needs, businesses can expand their capabilities more easily as technology evolves. This approach allows companies to build institutional expertise, create a robust data infrastructure, refine processes, and scale their predictive modeling efforts over time to maintain long-term advantages in their respective markets.
Predictive Modeling in Platforms
For all but the largest companies, the benefits of predictive modeling are most easily achieved by with ERP systems featuring built-in technologies and pre-trained machine learning. For example, planning, forecasting, and budgeting features may provide a statistical model engine that rapidly models multiple scenarios based on changing market conditions.
As another example, a supply planning or supply capacity function can similarly predict potentially late deliveries, purchase or sales orders, and other risks or impacts. The dashboard can also incorporate alternate suppliers to enable flexibility so companies can pivot as needed for manufacturing or distribution requirements.
NetSuite Scenario Planning and Modeling
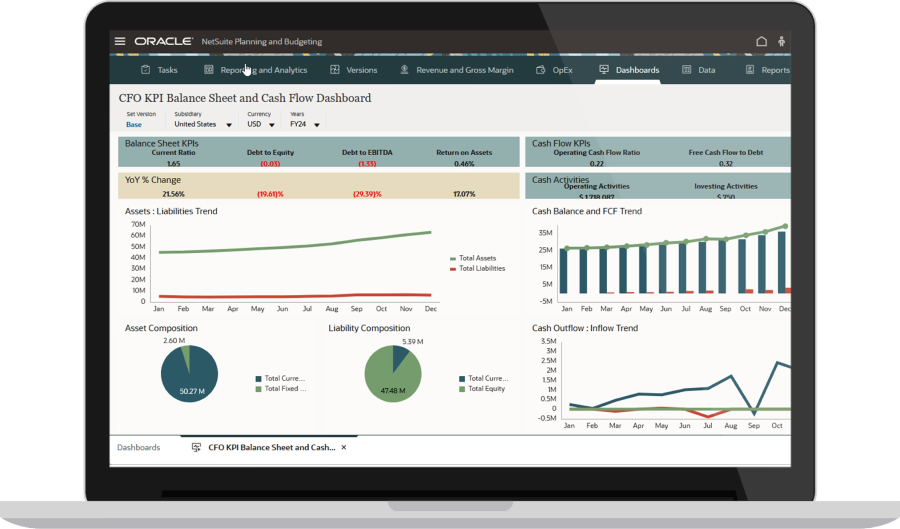
Large businesses have been using predictive modeling tools to enhance their financial planning and budgeting processes for decades. As technology has evolved, these tools have become increasingly accessible, enabling companies of all sizes to harness data-driven decision-making while managing both costs and organizational change. To get the most out of these tools, however, business leaders must understand their limitations and strengths. Then they can develop targeted strategies and best practices to consistently generate reliable insights about potential future outcomes.
Predictive Modeling FAQs
How does predictive modeling work?
Predictive modeling analyzes historical and current data to identify patterns and relationships that help predict future outcomes. These models typically use statistical techniques and machine learning algorithms to process large datasets and assess the probability of specific scenarios.
What is an example of a predictive model?
A common example of a predictive model is a credit risk assessment that analyzes a customer’s financial history, income, and other relevant data to assess the likelihood that they will default on a loan. The model compares this information against similar customer data to generate a risk score, which guides lending decisions.
How do you pick the right predictive model?
The right predictive model depends on a business’s objectives, budget, type and quality of available data, and desired prediction capabilities. When choosing among options, such as regression models, classification models, or time-series analysis, consider factors such as the model’s accuracy requirements, compute capabilities, complexity level, and existing IT systems.







