
Structured data is a fundamental, yet widely misunderstood building block of the information economy. The misunderstanding occurs because the concept of structured data has been applied to two different but equally important methods of creating, publishing and maintaining information in the modern world of connected commerce.
In both contexts, structured data can be defined as a controlled and hierarchically organized vocabulary used to describe and classify entities, be they news articles or a business's products and services. In organizations, structured data helps make information more accessible and easier to analyze, leading to deeper insights. On the internet, it helps make information and web pages become more discoverable. Structured data can be used to aid in content analysis, speed up on-site searching, improve search engine optimization (SEO) and generate new ways to display content.
What Is Structured Data?
Structured data can be thought of in two different ways:
1. As a method that helps optimize data to fit into fields in a database.
2. As a protocol for helping web pages describe themselves to search engines.
Structured data as a method for optimizing information is not new. As far back as 1873, a structured data model called the Dewey Decimal System revolutionized libraries by proposing books be organized by topic instead of when they were acquired. Consequently, library users had a much easier time finding all books on history and geography, for example, because they were all gathered in the same area. And since the Dewey Decimal System was multilayered, books on more granular topics — say, the history of the British Isles — became easier to find, too, because they were all stored together in a cluster within the broader category.
This is exactly how structured data works today, though the relational model implies no inherent order. The organization of the table would be based on the clustering key as well. Structured data — sometimes also called a taxonomy — is added to the database records to enable users to draw a comprehensive subset of entries about very specific topics.
Structured data as a protocol that helps optimize web pages that appear in search engines is new and has yet to be embraced by more than a minuscule fraction of websites. In this context, pages can either use structured data or not.
Where the two versions meet is the modern twist: Search engines are giant databases of web pages, which can use structured data to describe themselves — and, in so doing, optimize their ranking and appearance on search engine results pages. While no definitive taxonomy exists for all web pages, a website called schema.org has laid out a structured data protocol designed to help pages get indexed and appear in new ways within search engines. But few web pages actually use structured data. Schema.org says fewer than 1% of web pages use structured data to describe themselves — so using structured data represents a potentially huge competitive advantage.
Structured Data vs Unstructured Data
To visualize the essential difference between structured and unstructured data, consider email. Email combines highly structured data — defined fields such as timestamps, senders and recipients — with unstructured data fields such as the subject line and body text. Searching for all emails from a specific person quickly results in a comprehensive and authoritative list of all emails sent by that certain someone. But trying to find an email that mentions a particular phrase or concept is more problematic.
Why? The structure of an email address is very well defined. And while many people have more than one email address, they don't have an infinite number of email addresses. It can be relatively safe to assume that searching for a specific email address will provide a comprehensive and authoritative result. But the body of an email and the subject line have very few definitions attached to them and vary by the whim of the writer. Was the word plural or singular? How was the word used? Is the word even mentioned in the email? Perhaps it was misspelled. So it's quite challenging to process language and do a free text search of the unstructured content in the body or subject of an email and be reassured that the results are either comprehensive or authoritative.
This example shows the power of structured data as an organizing force that uses definitions to impose structure. Email addresses are well defined and can only be written in a certain way. Timestamps are based on possibly the most controlled vocabulary in existence: time. Unstructured data, by comparison, is not quite chaos but lacks the definitions that enable it to be confidently analyzed.
The Differences Between Structured and Unstructured Data
| Structured data... | Unstructured data... |
|---|---|
|
|
Key Takeaways
- Structured data is best thought of as two different things: a way to improve databases and a way to help web pages get indexed by search engines.
- Using structured data, businesses can conduct analyses to help them decide to modify their strategy or uncover new products to create.
- Websites use structured data to present their pages more effectively to search engines.
- Schema.org provides a comprehensive base set of structured data elements that major search engines have agreed to acknowledge.
Structured Data Explained
In its simplest form, structured data is information about other information that is optimized to be read by a computer. Anyone familiar with SEO will recognize the meta tag as perhaps the simplest form of structured data. Three specific meta tags — title, description and image — are hoovered up by search engine index protocols.
Structured data is a supercharged version of these meta tags, providing specific and granular tagging information that follows a controlled and hierarchically organized vocabulary. Elements like addresses, hours, reviews and much more — even physical dimensions of a product — can be explicitly spelled out. While Google states that structured data bears no weight on page ranking, it does convert some pages containing structured data into what it calls rich snippets, which are search-result listings that appear with extra elements like images and reviews.
But structured data's usefulness goes well beyond search engine optimization. Businesses that apply structured data to their internal databases can leverage it for analytical purposes. For example, structured data elements can be used to help a company discover new product opportunities. Consider a traffic analysis of a company's blog that shows a spike in readership about a certain topic; that could be a leading indicator of interest in a new product line.
Structured data also has implications in areas like machine learning and predictive modeling. As smart as computers have become, it's still difficult for them to draw certain specific details out of free-text articles. Structured data breaks the complexity down into many fielded elements, an environment optimized for computers.
How Structured Data Works
There are components of structured data that are universal. A good way to think of these is as existing vocabularies. Time, colors and addresses are types of structured data that do not need to be invented; they already exist and have some degree of universal acceptance.
Other structured data components are dependent on the needs of specific industries and companies. A structured data set for a pharmaceutical company is going to be different than the structured data set for a zoo. They will have overlap — address and logo might be two structured data elements they share. But it is unlikely that a structured data element describing "associatedDisease" — an element that the U.S. National Library of Medicine uses to denote diseases related to any given disease you might be reviewing — will be applicable to the zoo. It is similarly unlikely that a pharmaceutical company will need a structured data element for maximum attendance, which would be very useful to a zoo.
In a very practical sense, structured data is used to help people find the information they are looking for faster. Popularly, this is through search engines. A person might use a search engine to find drugs about a specific disease or the hours of the local zoo.
But structured data works in other ways, too. A news publication that tags every article with a structured data set describing the topic of the article can determine how many of its readers prefer one topic versus another, which could lead to discovering an opportunity to expand its business. In the same situation, the news organization could find that it has in-depth coverage of a specific topic and, connecting that with the site traffic statistics, could decide to roll out a new product.
To deploy a structured data set, it's critical to understand the industry to which the structured data will be applied. In some industries, structured data can be a competitive advantage and might be closely held. In other fields, it behooves players to share structured data.
Using Structured Data
Structured data can be written into a web page either as JavaScript Object Notation (JSON) (called JSON-LD, for linked data) or inline with HTML tags. The JSON-LD method is a set of code that appears in the page header and describes the entire page. The inline method describes the data within the HTML tags themselves. Which of these methods is used depends on the kind of data being structured.
For example, a web page that lists out retail locations would be best served by using the inline method, so that the address and hours of each location can be specified. This way, when a search engine indexes the page, this data may be included with the displayed search engine result. Alternatively, a web page about a specific product might use JSON-LD to put all the facts about the product, including the open text abstract, in one place on the page.
Why is structured data important?
Structured data can add a lot of value to content assets. One of its main benefits is to help make web pages more discoverable through search engines by potentially making them stand out from other listings. Structured data is also important because it can be used to analyze the effectiveness of data to help inform business decisions.
Why use structured data?
Structured data is a way for a company's website to convey its content information to search engines. While the largest search engine says that structured data is not technically a ranking factor, it's clear that structured data improves visibility. Google uses the structured data on web pages to generate what it calls "rich snippets" that display as special enhancements on search engine results. Whether they appear at the top or further down a search results page, rich snippets are far more prominent and visible than standard results and thus have better click-through rates.
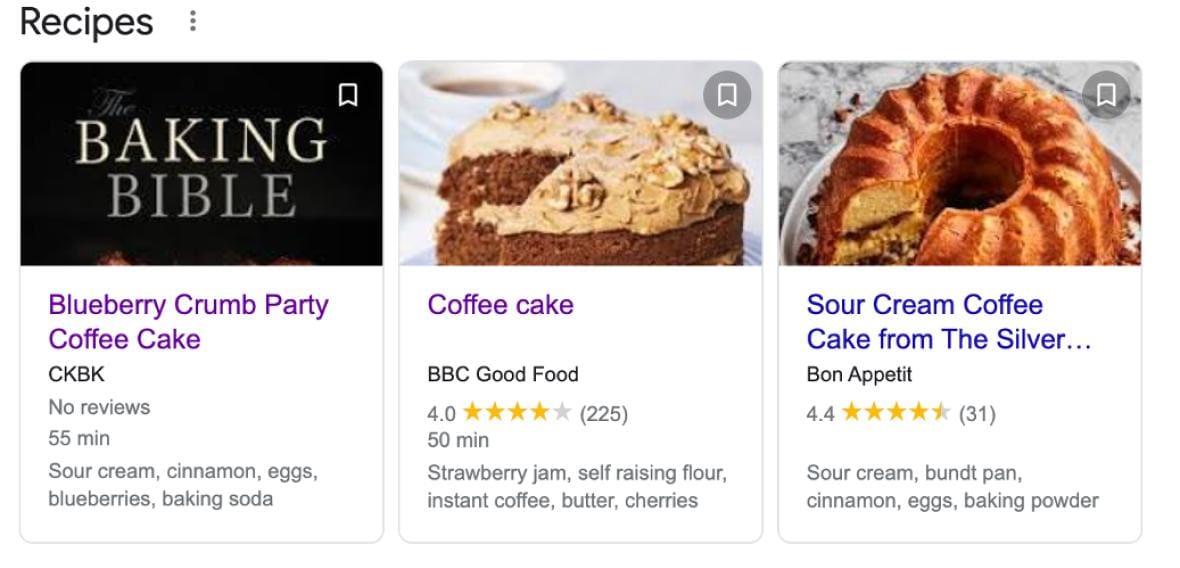
Take, for instance, a search for "party coffee cake." The first result is a carousel featuring recipes from three different websites. Google has used the structured data on these pages to determine that they match the searcher's intent and awarded them the topmost position. Without structured data, these rich snippet results would likely not have been in the top position.
It's important to note that including structured data does not guarantee that the search engine will convert it into a rich snippet. In fact, an analysis of the structured data of these three rich snippet items shows that the structured data for the second one is far more comprehensive than the structured data for the other two, so clearly other factors determine display order.
How is structured data used?
Structured data is used to describe information on both a local and global scale. Elements such as locations can amend structured data to help the specific address of a location be more readable for map placement. Product information can include an entire array of data about the product. And broader elements, such as information about a company and even the members of its board of directors, can have structured data attached to them.
Note how some of the carousel results above for the "party coffee cake" search show the expected preparation time. While a human reading the web page could easily see that the first recipe takes 55 minutes, Google learns this information through structured data: Listed on the page is a snippet of structured data ("prepTime":"PT55M") that says the dish takes 55 minutes to prepare. Google displays that information in the carousel.
Why Is Structured Data Important for SEO?
Structured data can make web pages appear more prominently in search results, which of course is the entire point of search engine optimization. A venue might display links to upcoming events. Other search results display images, ratings, recipe ingredients and other enhancements that make a listing in the search engine appear more prominent — all through the use of structured data.
With this prominence comes a higher click-through rate. SearchEngineLand.com says rich snippets can increase the click-through rate by as much as 30%. There is debate in the SEO community about whether listings with higher click-through rates get higher rankings. What is certain is that structured data can improve prominence, prominence improves click-through, and an increase in click-through means more traffic from the search engine.
How to Implement and Use Structured Data
It takes a concerted effort to create and deploy structured data on a set of web pages. There are two very compartmentalized steps to implementing a structured data system.
First, the structured data system must be created. This is sometimes referred to in an editorial context as the site taxonomy: determining the words and language that will be used to describe the data. Some structured data elements are self-defined: storefronts are locations, so they have geolocations and hours; products come in certain colors, have dimensions and very specific sets of features; and films have actors, a director, a writer, etc. Each of these examples relate to existing vocabularies — there is an existing vocabulary of colors, for example. Part of the editorial function in this step is to declare which structured data attributes are to be used.
But there are other elements that cannot rely on existing vocabularies. A product description or abstract of a creative work, for instance, is something that needs to be specifically created. A thorough review of the structured data components on schema.org is a good place to start, but the type of product the structured data is trying to describe often goes deeper than schema.org.
The second step is deploying the code for the structured data. Again, schema.org is a great resource, as it provides a variety of options for ways to deploy structured data on the page, all of which can be categorized in two ways: inline with the test via HTML tags or all in one place using JSON-LD.
It is precisely because these two steps are so compartmentalized that structured data on web pages has been adopted so slowly. These two steps require coordination between two traditionally disconnected groups in an organization: authors and software developers, or coders. If a company wants to take advantage of the benefits of structured data, it's important to create some sort of connection or mandate between the two groups.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Place",
"geo": {
"@type": "GeoCoordinates",
"latitude": "40.75",
"longitude": "73.98"
},
"name": "Empire State Building"
}
</script>
<div itemscope itemtype="https://schema.org/Place">
<h1>What is the latitude and longitude of the <span itemprop="name">Empire State Building</span>?</h1>
Answer:
<div itemprop="geo" itemscope itemtype="https://schema.org/GeoCoordinates">
Latitude: 40 deg 44 min 54.36 sec N
Longitude: 73 deg 59 min 8.5 dec W
<meta itemprop="latitude" content="40.75" />
<meta itemprop="longitude" content="73.98" />
</div>
</div>
How Google Uses Structured Data
In 2011, a consortium of search engines (Google, Bing and Yahoo!) collaborated to create schema.org, whose mission is to create, maintain and promote structured data on the Internet. The central hypothesis was that more information could be indexed more efficiently if content producers used schema — a set of machine-readable descriptors — to help search engines understand the content of a page.
Through schema.org, the consortium provides a broad set of hierarchical tables to assist in defining a wide range of information types. Each is broken down into distinct, related subcategories. For example, one such category is "Place," which then breaks down into nine distinct sub-types all related to the topmost category. Each of these breaks down further to explain, in great detail, the characteristics of the category.
For instance, consider a web page about the hypothetical Paradise Pond in southern New Hampshire. The Paradise Pond web page could have on-page instructions, or schema, that describes it as a "Place > Landform > BodyOfWater > Pond," incontrovertibly defining it in a way that search engines recognize. Subcategories provide other definitions that make the page about Paradise Pond more useful. One such characteristic, called "publicAccess," is a true/false indicator of whether the pond is accessible to the public. The value of adding longitude and latitude to the page — in addition to literally putting Paradise Pond on the (Google) Map — is that the web page can then become a reference point for articles about the general area.
It's important to remember that this structured data is not describing the pond but, rather, the page about the pond. One of the values of including schema elements such as geolocation and public accessibility is that, with such elements, a search phrase like "ponds in New Hampshire with public beaches" becomes more likely to return results that include our hypothetical Paradise Pond page.
<script type=”application/ld+json”>
{
“@context”: “https://schema.org”,
“@type”: “Pond”,
“name”: “Paradise Pond”,
“containedInPlace”: “Hampstead, NH, USA”,
“publicAccess”: true,
“isAccessibleForFree”: false,
“geo”: {
“@type”: “GeoCoordinates”,
“latitude”: “ 42.8696”,
“longitude”: “71.2147”
},
“description”: “Paradise Pond is a small pond in Southern New Hampshire (USA) distinctive for being divided in half by a large island called Governor's Island.”
}
Structured data adds enormous value for Google and other search engines because attributes such as public access are problematic for a search engine to discern. The presence of “publicAccess: true” in the page schema is simple and definitive.
Examples of Structured Data
Structured data can either use existing vocabularies or be custom-created for the specific needs of an organization. An existing vocabulary might be something as straightforward as Postal Codes (representing specific regions within a country) or a complex taxonomy of medical topics. The key is that the structured data must be authoritative.
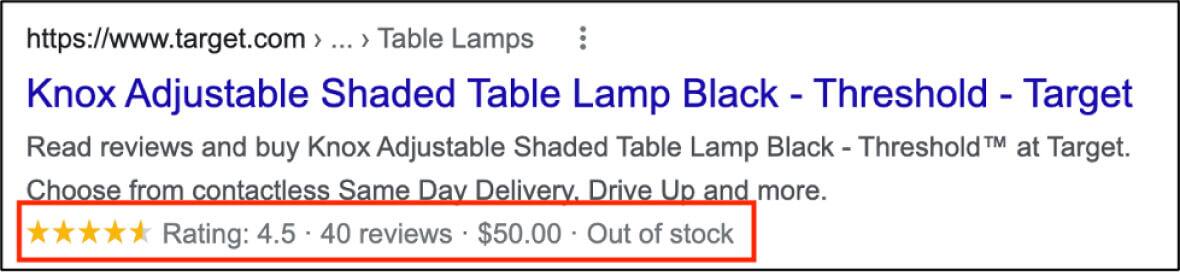
To tap into Google's rich snippet displays, big-box retailer Target.com uses structured data from the schema.org site to help search engines acquire the details about products. Beyond the product name, a URL for the image and a description, the site provides in-depth details in structured data, including the price, the SKU, stock information and customer reviews. The result: Google appends structured data information to listings that include Target products (see red-boxed portion in the accompanying screen capture).
The U.S. National Library of Medicine produces more than 100 health care research databases covering everything from AIDS to Viral Genomes. To make this vast and diverse resource more usable, they created a structured data system called the MeSH (Medical Subject Heading) thesaurus. Every record is catalogued by this structured data set, enabling a researcher to find very specific results across many data sets. The MeSH thesaurus has become a de facto standard.
Inventory management is awash with structured data. From the supply chain that delivers goods to a store to the bar code scanned at the cash register, nearly every transaction is governed by structured data. The ubiquitous bar code identifies not only the product but also the producer of the product. This data feeds directly into a store's systems, enabling inventory to be tracked and managed in near-real-time. This, in turn, enables stores to make rapid — sometimes automated — decisions about stocking and reordering.
In the early 2000s, the medical division of a tech publishing company used a custom structured data system to streamline its publishing processes. The division had evolved through acquisition, so each website used a different content management system, and, over the years, each developed its own business processes and systems. To consolidate, the organization built a taxonomy that combined each publishing system's keywords and generated a new, unified taxonomy that covered all sites. The result was a system that required fewer people to run it and enabled development of new products: Division leaders could use the taxonomy to generate new websites by selecting different mixtures of existing content based on the taxonomy tags.
Structured Data in Machine Learning (ML) and Predictive Modeling
Everything a computer does must ultimately come down to a binary decision. That means the data used to train even the most sophisticated artificial intelligence systems must be as precise and unambiguous as possible to support an algorithm's ability to make such binary choices well. This, of course, is where structured data shines, and why well-designed taxonomies are key to both machine learning and predictive modeling. Both thrive on a normalized vocabulary — ideally, a controlled and hierarchically organized vocabulary. However, about 70% of the tasks a data scientist does it data wrangling and cleaning.
Consider a training set for a machine learning project on home sales in the United States. It would require three primary bits of structured data: units sold, transaction date and zip code for each sale. All three of these use existing vocabularies: numbers, dates and locations.
But they do not tell a complete story; there are other factors that impact home sales. While the existing training set already inherently encompasses seasonality, weather also has an impact. This presents a problem because weather reports are not structured data, they are free text. At the same time, however, there are plenty of data points using existing vocabularies that contribute to those free-text reports: wind speeds, temperatures, relative humidity, precipitation — these are all structured data components that computers can use.
To be effective, the U.S. home-sales training set would need access to the structured data components that, combined, make up the weather in a specific region. Thus, the training set could contain a more complete picture of home-sales influences. Over time, the machine learning algorithm would learn how to adjust its predictive analysis of the coming weekend's home sales when a heavy rain is factored into the weather forecast.
Overall, there are four types of data used in machine learning: numeric, categorical (e.g., those wind speeds and temperatures from the weather example, which define certain characteristics of whatever is being analyzed), time series and text. Structured data helps convert all four from free-text into name-value pairs — a data value and the name that explains what it represents — that computers can understand. Such data is what's fed into the algorithms used for both machine learning and predictive modeling.
Conclusion
In the end, structured data has a simple and valuable purpose: to bridge the gap between human-written and machine-readable content. Almost every example in this article shows how structured data can be used to help computers understand more quickly what certain content elements are about. From a vacation resort that has "publicAccess" set to true to a database of articles showing which topics a news site's readers crave most, including structured data is a way of normalizing free-text content so that computers can make better use of it — which means businesses can get more out of their analyses, and websites can improve their chances of increasing their prominence among online search results.
Structured Data FAQs
What is structured and unstructured data with example?
Structured data is data that uses a highly defined and limited vocabulary. Take, for example, the “country” field in an online order form. Usually, this is provided as a drop-down list of all the countries in the world. This is structured data because it is predefined and limited. It ensures that all orders from a particular country — say Germany — use the same spelling or code. The value is that it's then possible to do an analysis of orders that came from Germany. If this country field was an open text box — meaning that the person ordering needed to write in the country name — this would be unstructured data. It would not be possible to do an analysis of orders from Germany because people might have entered the country any number of ways: Germany, Deutschland, Federal Republic of Germany, or any of an infinite set of potential misspellings.
What is an example of structured data?
Email addresses are a good example of structured data. The structure of an email address is very well defined. And while many people have more than one email address, they don't have an infinite number of email addresses. It can be relatively safe to assume that searching an email account for a specific email address will provide a comprehensive and authoritative result.
Does Google use structured data?
While Google states that structured data bears no weight on page ranking, Google does use structured data to help categorize content and to display additional information along with a search result. They call these “rich snippets,” and they can take the form of featured carousels at the top of the results page or as elements such as reviews and inventory availability appended to an individual listing. Whether they appear at the top of a search results page or further down, rich snippets are far more prominent and visible than standard results and thus have better click-through rates.
What is schema.org?
Schema.org was founded in 2011 by a consortium of search engines — Google, Bing and Yahoo! — as a way to encourage content publishers to use structured data to help describe their content in a way that is more readily machine-readable.
What is JSON-LD?
JavaScript Object Notation for Linking Data (JSON-LD) is one of the formats used for structured data. It is used to describe the contents of a page in a way that is machine-readable, particularly for search engines.
What is unstructured data?
Unstructured data is content that is not labeled in a way that computers can understand. Videos are unstructured because there is no way for a conventional computer to understand what the video is about. Often videos are accompanied by a transcript that makes their content accessible to online search.
Are hashtags structured data?
The now-common hashtag is a very loose form of structured data. While not always strictly used this way, hashtags are often used to describe a broader content category. Many web systems — Twitter being the most obvious example — convert hashtags into links that search data for other posts tagged with the same hashtag. While hashtags fail at being either controlled or hierarchically organized — two important attributes of structured data — they excel at helping information become more discoverable, which is the main purpose of structured data.







