

When the first bits were dropped on the first hard-disk drive, it’s not likely that computer scientists imagined the onslaught of data just 50 years would bring. But those pioneers probably recognized that data management was going to become a challenge. Part of meeting that challenge is data modeling: the practice of developing data storage and retrieval solutions that fit the requirements of a particular business.
What Is Data Modeling?
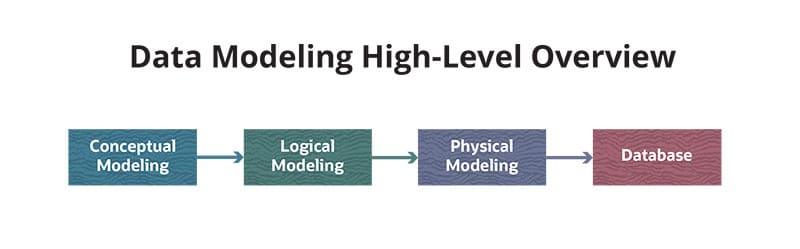
Data modeling starts with understanding the business needs of an organization and then understanding its data — the conceptual modeling stage. From there, the data modeling process defines data elements, the relationships among them and the data structures they form (logical modeling) in order to create a manageable, extendable and scalable data management system aligned with the needs and requirements of a business (known as physical modeling). The organization’s database is constructed based on that physical model. Data modeling is critical for any data-driven organization because it holds the needs and requirements of the business up against the organization’s data and optimizes the data for business use.
While it can be a fairly abstract topic, data modeling has a significant impact on how data is stored and retrieved, which translates directly to the kinds of reports that business leaders can get to help run their organizations and make pivotal decisions.
Data modeling vs data analysis
There is a symbiotic relationship between data modeling and data analysis. The output of data modeling is meant to make data mining and analysis more efficient and meaningful. More specifically:
-
Data modeling refers to the process of designing how data is stored and retrieved by an organization. It analyzes the needs of the business, applies pretested templates (or patterns) and best practices, and creates a database structure that can efficiently provide the business with the information and insights it needs.
-
Data analysis looks at an organization’s data, interprets the data and creates reports. Data analysis usually is either ad-hoc, meaning a specific report is requested when needed, or preplanned and delivered on a specific schedule.
Key Takeaways
- Data modeling applies the needs and requirements of a business to the design of a data storage system.
- Organizations that collect and use a high volume of data will find that data modeling ensures a higher quality of data.
- Data modeling provides a standards-based methodology for designing, managing and growing data assets.
- There are eight steps to consider in the typical data modeling process.
Data Modeling Defined
Data modeling is the process of developing a plan for how an organization wants to collect, update, organize, store and analyze data. In data modeling, key business concepts are mapped to available and prospective data so that the relationships between the concepts and the way data is warehoused can be visualized. The end result of data modeling is to give the business efficient and meaningful analysis and insights from its data.
Data modeling is highly technical, a bit arcane and interdependent with databases and programming languages. In other words, the choice of the database system in which data will be stored and the language used to describe a data model can influence the development of the data model. The good news is, modern business software, such as enterprise resource planning (ERP) systems, usually comes with preconfigured data models that can be used as is or customized.
Why Use Data Models?
A database is only as valuable as the faith an organization has in it. Data modeling helps support that faith by ensuring the organization’s data, which is often stored in your data warehouse, is accurately represented in a database so it can be meaningfully analyzed.
On a very tactical level, data modeling helps to define the database — the relationships between data tables, the “keys” used to index and connect tables and the stored procedures that make accessing the data efficient. On a higher level, however, the reason to use data models is to ensure that database designs are aligned with the needs of the business. Without input from business stakeholders, it’s very unlikely that subsequent data analysis will reveal useful insights or that data will be organized and stored efficiently.
Data modeling also provides a standards-based methodology for constructing, managing and growing data assets. By spending the time to create data models and incorporate data model patterns — best-practice templates for common types of data — an organization can make better use of the data it collects and can grow its data and teams more effectively.
Data Modeling Techniques
A variety of techniques and languages have been created to develop data models. The general idea behind data modeling techniques is to find a standard approach that represents the organization’s data in the most useful way; the languages help communicate the data model by defining standard notation for describing the relationships between data elements. Any language can be used to describe any technique.
Why an organization would use one technique and language over another has to do with domain knowledge within the organization and customer requirements. For example, companies that do business with the Department of Defense are required to use the IDEF1X markup language.
The most popular technique among data scientists is the Entity Relationship (E-R) Model and the most popular language is the Unified Modeling Language (UML).
Entity Relationship (E-R) Model
The E-R model diagrams a high-level view of an organization’s data and the relationships among them. As the name suggests, it models out the relationships between data “entities.” The E-R model also establishes critical concepts that the final database must support.
As an example, a medical research publisher may find that each research paper (or entity) it publishes has a one-to-many relationship with a table of authors because there can be more than one author to a specific entity. Similarly, each paper/entity has a one-to-one relationship with a table of medical specialties and a one-to-many relationship with a table of subscribers. The publisher’s E-R model will show that the author table must support an entity identifier allowing multiple authors to be attributed to the same research paper. The research paper table must support a specialty identifier to connect the papers to the specialty table.
If authors need to have a connection to the specialties database, the E-R model will establish how this is accomplished most efficiently. The example above allows for authors to be connected to specialties, but depending on how that data will need to be used, it may not be the most efficient connection. If needed, the E-R model will scope a connection directly between the author table and the specialty table.
While the E-R model is considered by many to be the best option for relational database design, there are also three other common techniques. They are the:
-
Hierarchical model, which looks like an organizational chart in which the main entity is in the single top position and the connected data extend, like roots from a tree, below. Data elements all have one-to-many relationships.
-
Object-oriented model, which defines the database as a collection of objects in containers arbitrarily defined by the developer, like lists and sets, and can link to related data that may or may not be in the actual database. However, object-oriented databases are not suitable for deep analysis.
-
Object-relational model, which is designed to bridge the gap between the limited data types of the E-R model and the arbitrary definitions created by the object-oriented model.
UML (Unified Modelling Language)
The Unified Modeling Language (UML) was developed as a standards-based way to describe the connections and relationships among different data entities in a data model. Although UML was originally developed to serve the needs of the larger software development universe, many of its core principles and notations apply directly to data modeling.
UML is important because it provides a common data modeling language that helps data professionals communicate about the data model. It’s conceptually similar to the way music notation enables a composer to convey his or her intentions to musicians and enables an orchestra to play the piece. UML allows a database modeler to create the blueprint that describes the attributes and behaviors of the data set in a way that a database administrator can execute.
Using UML, a database modeler can describe the specific attributes of data tables (i.e., entity types and field names) and can also describe the relationships between them (i.e., “customer_id” connects to the customer table). And it provides a map that database administrators can use in the ongoing management of data assets.
UML is not the only language used to notate database schema. Other languages include:
-
Information Engineering, which does not support data attributes of an entity. Instead, it advocates that attributes be modeled elsewhere or simply described in words.
-
Barker Notation, which is well-suited for many types of data models. It provides hierarchies that are several layers deep.
-
IDEF1X, which is a complex language used mainly by the Department of Defense.
Types of Data Modeling
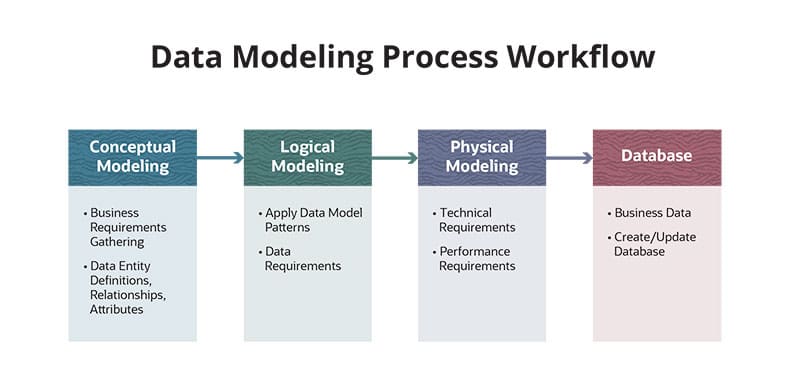
There are essentially three types of data modeling that, together, outline a best-practices process that takes data from business requirements through to creating the actual data stores: conceptual, logical and physical.
It’s helpful to think about these stages using a home-building metaphor. An architect takes the ideas, requirements and needs from a homeowner (conceptual data modeling), designs them into a blueprint (logical data modeling) and then a contractor constructs the home (physical data modeling). It’s important to note that data modeling builds the house — but the data hasn’t moved in yet.
Conceptual Data Modeling (or Enterprise Data Modeling)
The goal of conceptual data modeling is to organize ideas and define business rules. The main participants are business stakeholders and data modelers/architects. Business stakeholders outline what they need the data to provide, and data architects specify ways data can be organized to provide it.
For example, a business stakeholder may have a requirement that sales figures are available and always “up-to-date.” Since “up-to-date” can mean different things to different people, the data modeler looks to eliminate ambiguity by defining what “up-to-date” means to the stakeholder. The difference between “up-to-the-minute” and “as-of-the-end-of-yesterday” have very different implications for system complexity and costs. Similarly, defining vocabulary is an important part of conceptual data modeling. It ensures that disparate team members know, for example, what is meant by “up-to-date,” and that they all use the term to mean the same thing.
Among other key elements to work out during the conceptual phase are:
- Data entity definitions
- Entity attributes
- The relationship that must exist among data entities
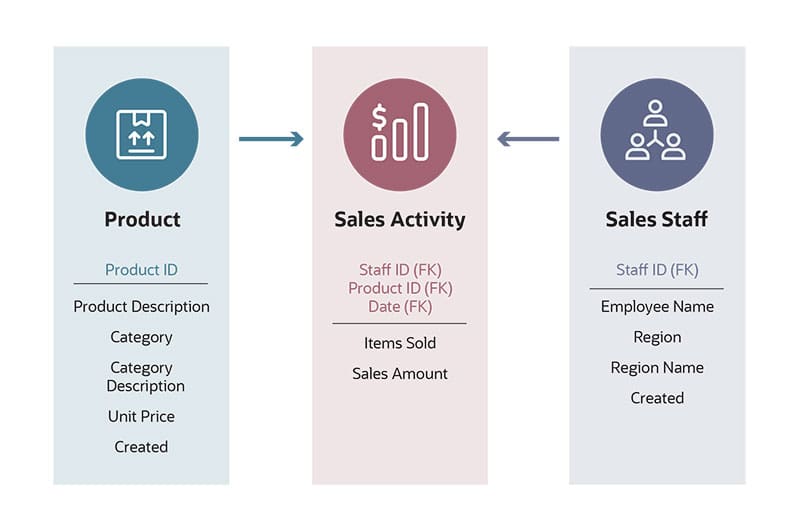
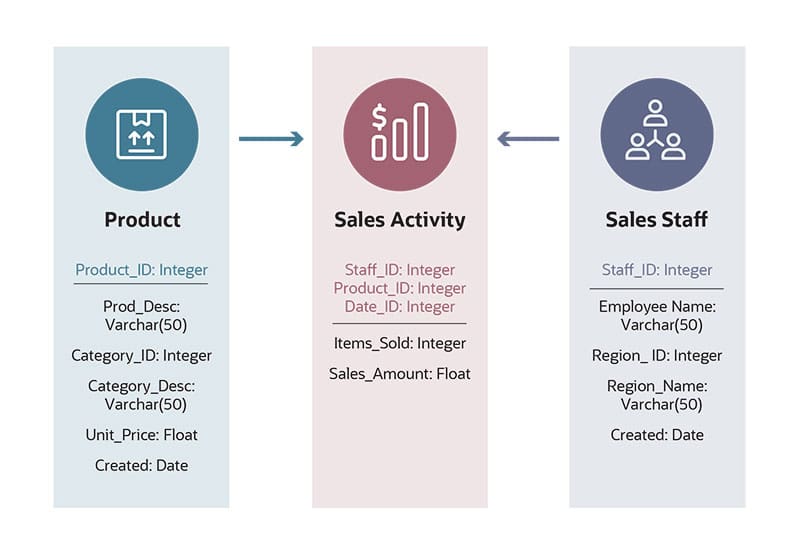
For example, sales activity and sales staff are two entities. Each of these entities has certain attributes. Some attributes of the sales activity entity might be which product was sold and by which account manager. The sales staff entity has a wholly separate set of attributes, some of which most certainly are the salesperson’s name and the region or market segment they represent. There is a relationship between them because sales staff creates sales activity.
The data modeler will note that the sales activity table needs to connect to the sales staff table by way of an employee identifier. In all likelihood, products and customers are also entities with their own attributes and will be referenced in the sales activity table by identifiers that link to product and customer tables.
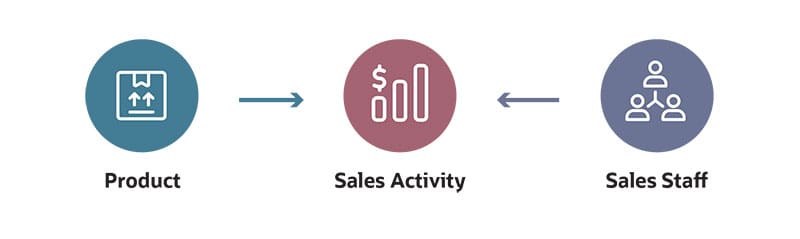
A key component of the conceptual data modeling phase is to look at business concepts across the organization and to resolve differences that might exist for the same information from two different departments.
Logical Data Modeling
The goal of logical data modeling is to bridge the conceptual and physical models — it translates the conceptual model into a set of instructions that can be used to create the physical model. During this “blueprint” phase, the structure of the data and the relationships among them are defined and the entire database plan is laid out with the connections between entities diagrammed.
For example, a logical data modeling plan will note that the sales activity table contains a product identifier that follows an alphanumeric format used to look up product information from a separate product table. It will also show that the sales activity table contains an order number used to connect with the financial table(s), but the order number will bear no connection to the product table.
Thus, the output of logical data modeling is a kind of manifest documenting the needs and requirements of disparate parts of the organization in a single overall data management plan. It’s an important document.
Physical Data Modeling
It’s time to build the home. As the name suggests, physical data modeling gets into the physical specifics of database storage: what data is collected in what columns, in which tables and how those tables are specifically connected. Table structure, primary, secondary and foreign keys — codes used to identify data relationships — and indexes are fully defined.
It’s during physical data modeling that specific database management systems (DBMSes) are addressed. Different DBMSes have various limits in terms of size and configuration, so it’s important to choose a DBMS that meets the needs and requirements of the data model.
Advantages of Data Modeling
Data systems that have gone through data modeling have many advantages, especially for organizations that collect and use a high volume of business data. Possibly the most important advantage is the data modeling process ensures a higher quality of data because the organization’s resulting data governance, or a company’s policies and procedures to guarantee quality management of its data assets, follow a well-thought-out plan.
A proper data modeling process also improves system performance while saving money. Without the data modeling exercise, a business could find the systems they use are more extensive than needed (thus costing more than they need) or won’t support their data needs (and performing poorly). Another advantage of data modeling is so much becomes known about the data (type and length, for example) that organizations can create applications and reports that use data more rapidly and with fewer errors.
A good data modeling plan will also enable more rapid onboarding of acquired companies, especially if they also have a data modeling plan. At the very least, the acquired company’s data modeling plan can be used to assess how quickly the two data sets can be connected. What’s more, the existence of a plan will expedite conversions to the acquiring company’s systems.
Disadvantages of Data Modeling
Data modeling is not for every organization. If an organization does not use or plan to collect a substantial amount of data, the exercise of data modeling might be overkill.
For organizations that consider themselves data-driven and have — or plan to have — a lot of data, the main disadvantage of data modeling is the time it takes to create the plan. Depending on the complexity of the organization and the spectrum of data being collected, data modeling might take a long time.
Another potential disadvantage depends on the willingness of non-technical staff to fully engage in the process. Integral to data modeling is that the business needs and requirements are as fully described as possible. If business stakeholders are not fully engaged in the data modeling process, it’s unlikely that data architects will get the input they need for successful data modeling.
Examples of Data Modeling
Consider this example of a small hotel chain to illustrate the role of data modeling and its importance to business decision-making. The hotel chain books rooms through three channels: it’s a call center, a website and many independent travel sites. The independent sites are problematic because they take a commission and the hotel chain must spend extra to make it to the top of search results.
Data modeling reveals the importance of tracking independent travel site data in coordination with other data so that the hotel chain can decide where to spend its money. The data modeler notes that sales source information must be tracked by each independent travel site (i.e., channel) so that the business can decide the value of each. Additionally, the data must connect to two other data sets: commissions paid for orders and advertising spend. This way, a report or dashboard can be created showing the cost of sales that came through each channel. The business can use that report to determine which independent travel sites are most profitable and adjust its spending accordingly.
Without going through the data modeling process, it’s likely that the sales and commissions tables would be naturally connected but the advertising spend table might not. Without data modeling, the advertising spend information may not be accessible at all because it is held in department-level spreadsheets. It’s the process of data modeling that brings this information together, setting requirements for data entry when needed, so that the business can get actionable data insights for decision-making.
How to Model Data
Once data modelers have obtained a thorough understanding of a business and its data, they’re ready to begin the data modeling process itself. A solid data modeling process typically consists of the following eight steps.
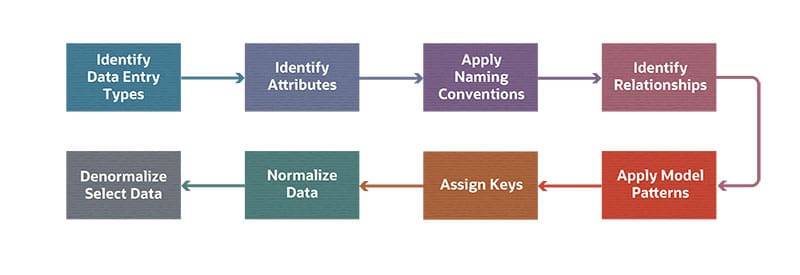
8 Steps to Data Modeling
-
Identify data entity types: Entity types depend on the specific type of system being constructed. But there are many common entity types, such as sales, customers and employees. A thorough audit and data crunching, or the automated processing of enormous amounts of data, is needed to identify an exhaustive list of entity types. By nature, many entity types (such as customers and sales) might be universally accessible within the organization. But there are also entity types, such as financial data, that need secured access. And there will be some entity types, such as website traffic, that may have little bearing outside of a specific department. All of this must be captured in the entity type definitions.
-
Identify attributes: Each entity type then needs to be defined in terms of its specific attributes. Attributes are the set of fields that go into describing a particular entity. For example, the employee entity type will have attributes such as name, address, phone number, ID badge number and department. It’s important to be thorough. It’s not that attributes or entities can’t be redefined later, but being thorough early in the process avoids later pitfalls.
-
Apply naming conventions: It is also important that the organization set up and use naming conventions along with their definitions. Standard naming conventions allow people to communicate needs more clearly. For example, the hotel chain that pays independent travel sites a “fee” for every sale might want to consider using the word “commission” instead to be more logically compared with the commission paid to the call center sales staff. Also, since the hotel chain pays independent travel sites fees for advertising, it would reduce ambiguity about what each word describes.
Where this is specifically important in data modeling is in the efficiency with which people can interact with the final system. Using the hypothetical hotel chain example, imagine an under-informed employee requesting a report that shows the fees paid to independent travel sites to make a judgment on which sites to increase spending. If “fees” and “commissions” are two separate pieces of information, the resulting report would not be accurate because it looks at fees alone and does not include commissions. The business might make some detrimental decisions because of this faulty information.
-
Identify relationships: Connected data tables make it possible to use a technique known as data drilling, or the different operations performed on multidimensional and tabular data. The best way to see this is by thinking about an order. The specific phrases used by UML are italicized: Using UML, an order is placed by a customer having potentially multiple addresses and is composed of one or more items that are products or services. By representing relationships in this way, complex ideas in the data model map can be easily communicated and digested at all levels of the organization.
-
Apply data model patterns: Data model patterns are best-practice templates for how to handle different entity types. These patterns follow tested standards that provide solutions for handling many entity types. What’s valuable about data model patterns is they can underscore elements that may not have been obvious to data architects in a particular data modeling exercise but are contained in the pattern due to extensive prior experience. For example, the idea of including a “Customer Type” table — which opens up the possibility of doing analysis based on different types of customers — might come from a data model pattern. Data model patterns are available through books and on the web.
-
Assign keys: The concept of “keys” is central to relational databases. Keys are codes that identify each data field in every row (or record) within a table. They’re the mechanism by which tables are interconnected — or “joined” — with one another. There are three main types of keys to assign:
-
Primary keys: These are unique, per-record identifiers. A data table is allowed only one primary key per record, and it cannot be blank. A customer table, for example, should already have a unique identifier associated with each customer. If that number truly is unique in the database, it would make an excellent primary key for customer records.
-
Secondary keys: These also are unique per-record identifiers, but they allow empty (null) entries. They’re mainly used to identify other (non-primary) data fields within a record. The email address field in a customer table is a good example of a secondary key since an email address is likely to be unique per customer, yet there might not be an email address for every customer. Secondary keys are indexed for faster lookups.
-
Foreign keys: These are used to connect two tables that have a known relationship. The foreign key would be the primary key from a record in the related table. For example, a customer table might have a connection to a customer address table. The primary key from the customer address table would be used as the foreign key in the customer table.
-
-
Normalize data: Normalization looks for opportunities where data may be more efficiently stored in separate tables. Whenever content is used many times — customer and product names, employees, contracts, departments — it would likely be better and more useful to store it in a separate table. This both reduces redundancy and improves integrity.
A good example is customer information in an order table. Each order naturally includes the name and address of the customer, but that information is all redundant — it appears as many times as there are orders in the table. This redundancy causes many problems, not the least of which is that every entry must be spelled exactly like all other entries for searches of that table to work. To reduce this redundancy and improve data integrity, the customer information data is normalized by being placed into a separate “customers” table along with all the relevant customer information. Each customer is assigned a unique customer identifier. The order table is then modified to replace the customer information fields with a single field referencing the customer’s unique identifier. This process of normalization improves the integrity of the data because a single authoritative source — the “customers” table — governs all references to the customer.
Another benefit of normalization is it enables faster database searches.
-
Denormalize (selected data) to improve performance: Partial denormalization is sometimes needed in specific circumstances. Normalization generally makes for a better, more accurate database with more individual tables that can be quickly and accurately searched. But not always. The cost of more tables is more “joins” connecting tables in the event of complex queries. Individually, joins have a virtually imperceptible performance cost. But they add up for complex queries.
Take, for instance, fans interacting with a ticketing system for concerts. A fan selects seats and the system must prevent those seats from being purchased by someone else until the customer makes a decision. If they choose not to buy the seats, or the time limit expires, it’s important that the seats become immediately available for other customers. To support this high-volume transaction system, the data professionals architecting the system might recommend a section of the database be denormalized so that all the core transaction elements — seat numbers, venue, concert date, performing artist, etc. — exist in as few tables as possible, ideally one. So instead of a query that joins the venue information with tables for the artist, date and seat numbers (all likely normalized into separate tables), it will be a faster transaction if the normalization of these tables or these fields are reversed.
Not all tables need to be denormalized, and each one that does will have performance as its most critical requirement. It all depends on the need for speed, and it might be that a fully normalized database meets the business’s performance requirements.
Industries That Use Data Modeling
Industries that tend to benefit from data modeling include any that uses a high volume of data to manage its business. Data modeling increases in importance for industries that use data as a core to their business, especially when privacy concerns and government regulation are added to the mix. Here are the industries that benefit the most from data modeling:
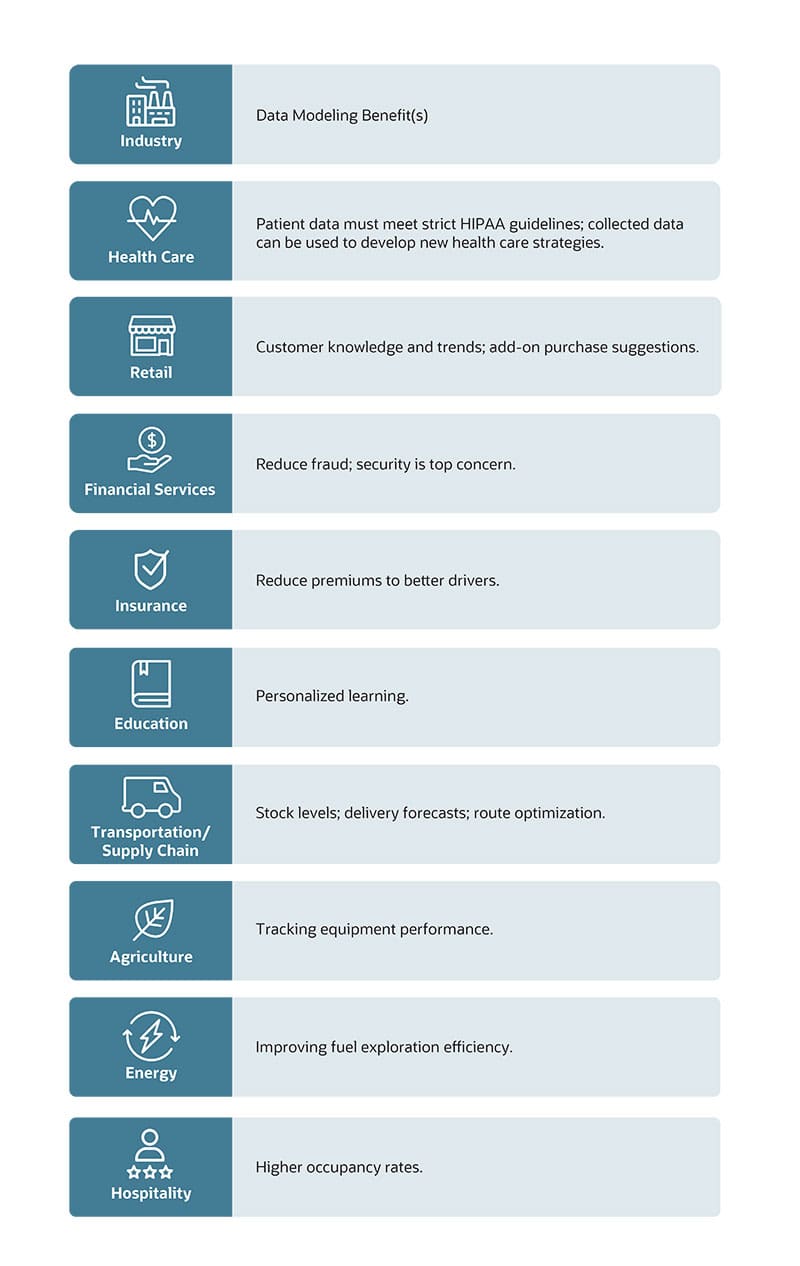
This is by no means an exhaustive list of industries that can see benefits from data modeling. Government, professional services, sports teams and other industries can also see big benefits from data modeling.
Data Modeling Tools
Various software applications are available to help data architects visualize data models. They don’t do the data modeling but rather help to manage the data model.
Typically, data modeling tools visualize the data tables and the relationships among them. As these maps can be vast, with hundreds of thousands of entities visualized, they have navigational functions such as search and zoom that allow data professionals to narrow or expand their view of the model.
Data modeling tools are especially valuable for reference in ongoing database management. If a new entity type is launched, visualization from a data modeling tool can help to make sure the specifics of fields are correctly created.
History of Data Modeling
The history of data modeling mirrors the history of computers, databases and programming languages, which all evolved together. In the 1960s, hard drives started to store larger amounts of information, and data management became a growing challenge. As disk capacities grew, the three main database formats in use today were first theorized: hierarchical, network and relational.
IBM pioneered the hierarchical model, whose data is structured like an org chart: Each “parent” in the hierarchy can have many “children,” but each child can have only one parent. General Electric developed the network model: Each parent and child data element can have multiple parents and children of their own. A bit later — the mid 1970s — IBM developer Edgar Codd came up with the idea for relational databases: data arranged in interconnected tables of rows and columns. IBM stayed with its hierarchical databases and didn’t pursue relational databases at first. But other organizations did, most notably Software Development Laboratories, which changed its name to Relational Software Inc. in 1979 and to Oracle Corp. in 1983. By the 1990s, the relational model came to dominate the database market, though hierarchical and network models are still used in certain industries and for specific applications.
As more companies began deploying relational databases, Peter Chen at Carnegie-Mellon University created the Entity Relationship (E-R) Model for data modeling.
By the mid 1990s there was explosive growth in PC and storage technologies, and efficient database management became a paramount concern. A group at Rational Software created UML with an aim to improve collaboration in the modeling of data systems, and UML was ultimately codified as a standard for data modeling.
Toward the end of the 1990s, the concept of non-relational databases, also called NoSQL, emerged. NoSQL databases use the brute force of modern computers — unimaginable in the 1970s — to search through massive amounts of structured and unstructured data stored without a predefined model or schema. The revolutionary concept behind NoSQL databases is that because data is stored in a structureless way, different data models can be applied to the data after it’s stored, depending on the business’s situational goal at the time or the specific application.
Data modeling and its interdependent influences — computers, databases and programming languages — all continue to evolve.
Future of Data Modeling
The sheer volume and diversity of data — structured and unstructured — continues growing at previously inconceivable rates thanks to the digitization of virtually all aspects of business and life. This includes everything from 4K videos and images to texts, emails, smartphones, smart watches, health trackers and internet of things (IoT) devices. In this data-rich future, it is the effectiveness of data modeling that will determine how much of this data is accessible and how well it can be used.
Data modeling in the future will:
- Add structure to enormous volumes of unstructured information
- Help determine what and how much of this information is accessible and for what time
- Architect the data systems that traverse structured and unstructured data
Imagine a police force of the future armed with smart badges that, among many other benefits, geo-locates every officer. This quickly amasses a significant amount of data, much of which is unimportant — but can suddenly become critically important under certain circumstances. While current location will be important to determine dispatch schedules, the historical information about police presence could be overlaid with other maps to have implications on broader planning. Add into the mix a feed from the police officer’s body camera and, not only will even greater amounts of unstructured data be generated, the importance of being able to reference the video by officer location doesn’t seem too futuristic at all.
Conclusion
As long as human activity in general, and business activity in particular, continues to generate rapidly accelerating volumes of information, making purposeful use of all that data will remain a growing challenge. Data modeling has evolved into a well-defined process with an associated set of tools through which organizations can shape data to fit their purposes. It is necessary for any data-driven organization that hopes to get the most value out of its data for business decision-making. Data modeling developed in concert with computers, databases and programming languages beginning in the early 1960s, is already a proven and effective method for creating responsive data storage systems — and continues to evolve.
Data Modeling FAQ
Q: What is data modeling used for?
A: Data modeling is used to structure a company’s data assets so they are efficiently and accurately stored and can be retrieved and analyzed to help the company make business decisions.
Q: Why use data models?
A: Data models establish a manageable, extensible and scalable methodology for collecting and storing data. The map that data modeling creates is used as a constant reference point for data collection and improves the ability of a business to extract value from its data. Companies that work in highly regulated industries find that data modeling is an important part of meeting regulatory requirements. Even non-regulated businesses can benefit from data modeling because it puts the needs of the business in the driver’s seat.
Q: What are some examples of data modeling in practice?
A: Data modeling looks at a business’s data and identifies different types of data and the relationships among them. For example, a customer file generally includes a series of components that describe it. There are data elements such as company name, address, industry, contacts and previous projects. There might even be data such as emails sent to people at that company. Depending on the business needs of the organization, a data modeler might design a database system with a table for basic company information that is linked to ancillary tables for contacts, previous projects, email conversations — and maybe a social feed made up of posts from people at that organization.
Q: What is data modelling in data analysis?
A: Data modeling is the plan for how data will be stored and accessed. Data analytics is the use of that data to create and analyze reports that a company can use to help make business decisions.
Q: What are the eight steps of data modeling?
A: Data modeling goes through eight discrete steps: identifying data entity types; identifying the attributes associated with them; applying naming conventions; identifying the relationships between data types; applying patterns (or templates) to make sure best-practice models are used; assigning keys that identify how the data is related; normalizing the data for efficiency and accuracy; and denormalization of specific data elements only for situations where speed trumps efficiency.







