

Buried in the source code of most web pages are a series of tags that describe their contents. Unseen by the casual visitor, these tags, collectively known as metadata, can be crucial to improving page visibility on search engines and social media. Other types of metadata surround us, too. For example, nearly every modern digital camera captures technical metadata for each photo, such as where and what time it was taken and its dimensions. Meanwhile, content management systems and digital asset management systems are built around structural metadata, which provides such information as how a document is organized or how an asset has been used. But regardless of type, the purpose of metadata is the same: It helps businesses more easily find and use their resources amid ever-growing volumes of data.
What Is Metadata?
Metadata is frequently described as “data about other data.” Whether detailing the contents of a web page, the technical details of an image, or information about an asset's usage rights, metadata provides additional information that facilitates data management so assets can be located and used more efficiently. In fact, metadata is mainly designed to be machine-readable — for example, metadata for a web page helps search engines understand and categorize pages — and is invisible to the casual site visitor. Likewise, the metadata in a photograph allows an image to be properly categorized and easily found in a digital asset management (DAM) system. Metadata also has major implications in the universes of information-sharing, usage rights and content reuse.
In 1995, the Dublin Core Metadata Element Set identified 15 elements common to most types of digital information: contributor, coverage, creator, date, description, format, identifier, language, publisher, relation, rights, source, subject, title and type. Since then, metadata has become integral in virtually every digital system that handles content.
Key Takeaways
- Metadata provides additional information about other data.
- There are three kinds of metadata: descriptive, structural and administrative.
- Metadata offers a company a level of control over what's seen when its content appears in search engine results and shared on social media and other enterprise programs.
Metadata Explained
A handful of studies have quantified how much time it takes employees to search for data — as much as two hours daily. This is where metadata can help. Global research firm Gartner defines metadata as “information that describes various facets of an information asset to improve its usability throughout its life cycle. It is metadata that turns information into an asset.” Harvard Law School likens metadata to an “electronic fingerprint” containing “identifying characteristics” that are hidden within a file.
A good way to understand metadata is to imagine searching a repository of images or videos.
Images and videos themselves can't be searched; rather, the information about them is
searchable. That information is metadata, and it's stored as meta tags, such as
<title> and <description>. When an art director, for
example, queries the company's DAM tool for a high-quality video of a bouncing ball for
a new web page, he or she is actually tapping two pieces of metadata: the definition of the
image (minimum 1080 pixels) and its descriptive tags (ball, ball bouncing). Videos whose
tags don't match won't appear in the art director's search results. Videos
(and images) will often also contain information about how the video has been used along
with crediting requirements — this, too, is metadata. Say the art director wants to
exclude videos that have previously been used. Metadata will know that information and
narrow the search to exclude those videos.
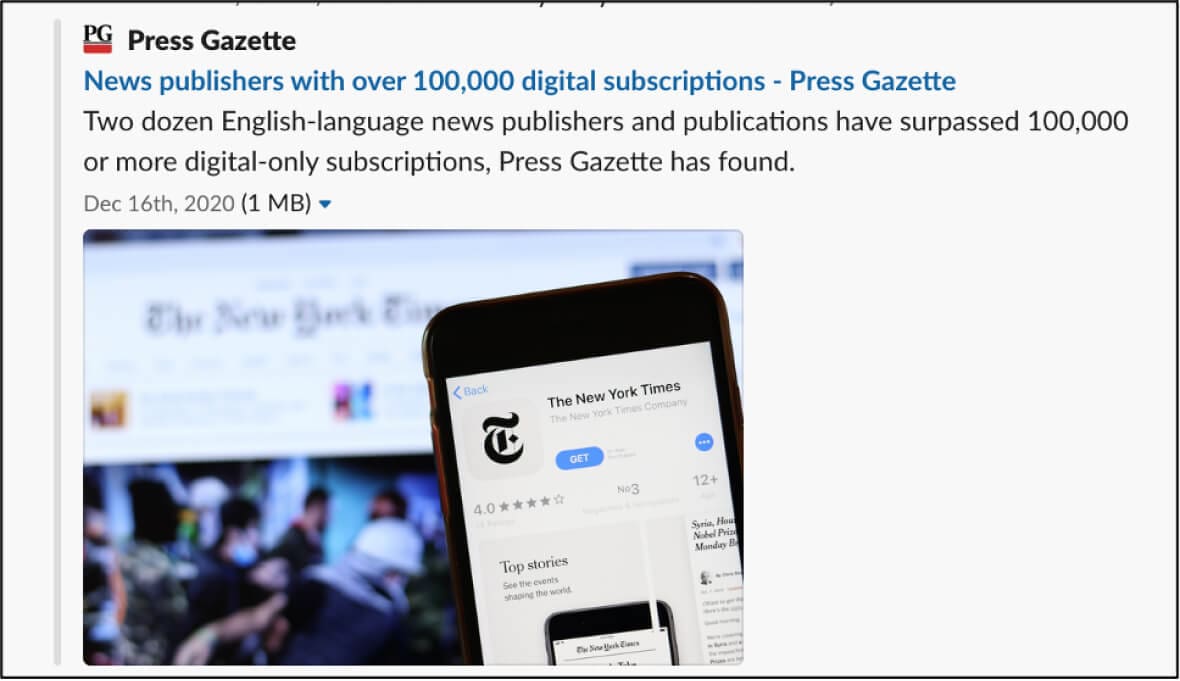
When that new web page goes live, search engines and social media sites rely on the page's metadata for proper indexing and sharing. Three primary tags generally come into play and are visible to viewers in their search engine results pages (SERPs): a title tag, or the content's headline; a description tag, which provides additional information about the page; and an image tag, which pulls in and optimizes the image for display. The end result: When the page is indexed by a search engine or shared on social media, it has the best possible chance that the right people will click on its link.
How Does Metadata Work?
Metadata performs a variety of functions. For instance, metadata that's captured with a digital image helps searchers locate images in a digital asset management system that meet or exceed certain dimensions. Similarly, metadata for an article in a content management system provides information such as the writer and copyright information so that the piece can be properly credited.
In addition, meta tags provide organizations with some control over what people see when content is delivered via search engines, social media and other collaboration tools, such as Slack and Messenger. There are three key pieces of metadata that help control what people see:
- Title: The title of the page (
<title>). - Description: A brief description of the page.
(
<meta name="description" content="...">). - Image: The URL for an image
(
<meta name="og:image" content="...">).
For any piece of content, web search engines generally deliver a headline, a description (or “snippet”) of the content and a link to the page. Search engines typically use the contents of the title tag as the headline in search results and the contents of the description meta tag as the snippet. (For a variety of algorithmically related reasons, search engines often rewrite description tags and, sometimes, title tags.) For example, a search for "ERP software" yields:

The inclusion of an image meta tag gains importance in social media and other sharing environments. For their part, Twitter and Facebook have released their own proprietary meta tags to make pages more shareable. But in the absence of those tags, the social sites rely on the headline, description, image and page link tags to display shared content.
Ontology of Metadata
With roots in ancient philosophy, ontology is a concept that helps specialized communities share common understandings. Per Stanford University, "an ontology defines a common vocabulary for researchers who need to share information in a domain." An ontology classifies things — in this case, data — as individual items that belong to classes or sets and defines specific attributes and relationships between them.
In academic and scientific communities, individual content is often viewed as a contribution to a larger understanding of some greater topic. Whether it's healthcare research about the latest flu strain or an essay on Sylvia Plath's earliest influences, much of the content adds to a broader body of work. Domain-specific ontologies restrict definitions and classifications to a specific field or area. An example is the "Disease Ontology," a standardized ontology that helps the biomedical community navigate authoritative content by drilling down into classifications and sets.
Different fields of business can be thought of as specialized communities, too, each one determining its own domain-specific ontology in the form of metadata for data interpretation. For example, oatmeal maker Quaker Oats developed an ontology to manage data generated by its oat breeding trials around the world. Given the volume of data generated by these trials, the specialized vocabulary enabled scientists and partners worldwide to find and make use of the data. It also became part of the broader agricultural market's Crop Ontology.
Savvy digital marketers will establish an ontology for the metadata used by their companies to describe the business and its content. These ontologies — sometimes referred to as taxonomies — help guide the creation and organization of content and can be used as part of usage analysis.
Why Is Metadata Important?
Metadata provides a structured method for communicating information about content. It is important because it makes finding, using and preserving that content easier by providing a standard mechanism and vocabulary. It also plays a significant role in search engine optimization (SEO). While it's possible to search one's computer or the internet for text-based documents, searching for an image or video in a repository is almost impossible without meta tags that describe them. Another reason meta tags are important is because they're virtually the only control a site has when its content is shared on social media or indexed by search engines; the tags inform the displayed information. They are worth paying attention to because proper presentation of the headline, description and image can mean the difference between getting the click or being ignored.
How Is Metadata Used?
On the web, metadata is used to convey information to search engines and social sites to inform the presentation of content. For longer-form documents, metadata is used in structural ways to indicate organizational elements, such as sections and page numbers. Metadata is also used to store important administrative details, such as usage rights and copyright information.
Other meta tags influence search engines as well, the most important being the "robots" tag, which instructs search engines on how to crawl and index a web page. This tag is critical from an SEO perspective: If a robot tag tells a search engine not to index the page ("noindex"), then it won't appear in any search results. It may also instruct crawlers not to follow page links ("nofollow") or to display the page's snippet on a SERP ("nosnippet"). Interestingly, the robots tag is only required to tell a search engine what not to do; there is no need to include a tag telling the search engine the page can be indexed.
Types of Metadata
There are three distinct types of metadata: descriptive, structural and administrative. Each one plays a different role in data and document management, whether those meta tags are web-facing or are used within other applications.
Descriptive metadata:
As the name suggests, descriptive metadata tags describe the contents of a document. They include elements such as title, description and image, as well as author name, date of publication, subject and publishing organization. Descriptive metadata is useful for finding a document in a large set of files, for example.
On the web, descriptive meta tags help search engines properly categorize an asset. They can also contain other types of data, such as the author/creator and relevant keywords, which are useful for search functionality within a website. For example, blog posts can often be displayed by a specific author or on a specific topic. These pages are typically generated based on author and topic metadata.
Structural metadata:
Structural metadata tags describe the relationship between parts of multipart objects. They cover how a document is organized and connections between assets, as well as facilitate content reuse. For instance, a DAM system may use structural metadata to record where a particular image was used. This can help prevent a large organization from using the same image to promote two different products, and can ensure usage rights are not violated.
A good way to think about structural metadata is as the table of contents for a long-form asset. The table of contents provides a list of the titles of sections or chapters, along with a link (or page number, depending on the format of the asset) to the actual content. In other words, a table of contents is the representation of the structural metadata. What this implies is rather remarkable. Since each title is associated with the text of a section, structural meta tags open the possibility for the content to be delivered in different ways far easier than would otherwise be possible. For instance, if a company wanted to release individual sections of a longer work, it is structural metadata that is called into action.
Administrative metadata:
More technical aspects of a file — creation date and file type, for example — are part of administrative metadata. Searching for files created within a specific time frame, for instance, makes use of administrative metadata. Administrative data has three sub-types:
- Technical metadata: Elements that help a computer understand file type and how it can be decoded. For example, for the computer to understand that a file is an image, it will be encoded with metadata such as jpeg, png or gif. This tells the computer not only that the file is an image but also what kind of image it is.
- Preservation metadata: Data that covers the archival and long-term management of an asset. This metadata might contain an indicator of the file size (technically known as a "checksum") so viewers can be sure they are looking at a complete file. In practical terms, preservation metadata is rarely used.
- Rights metadata: Indicates intellectual property ownership and usage rights. For example, a stock photograph may carry a meta tag stating the license agreement under which it may be used. This is often represented as a URL that points to a rights document.
Metadata Structures
In practice, metadata is most effective when it's based on well-defined taxonomies, vocabularies and ontologies, and is consistently structured across all of an organization's content. Think of the elements of a metadata structure as being "classifications" for content. An article, blog post or even an entry into a CRM have certain classifications that help define them. An article about pie charts could be classified as about Graphs, and thus a metadata topic of Graphs should be part of the defined taxonomy. An entry into a CRM is generally "owned" by someone; so "Owner" should be part of the metadata structure for the CRM.
Well-defined metadata structures have several certain characteristics in common:
-
Syntax:
Metadata syntax is defined by the markup or programming languages used. Generally speaking, tags will help define the meaning and purpose of the metadata in a way that a machine can understand. In the example of the metadata tags used to help search engines understand a page, this syntax is
<meta name="description" content="...">. The search engine's indexing tool looks for tags that begin with "meta," and then knows that the one named “description” will contain the publisher's own description of the page. -
Schemata:
Schemata helps define relationships between elements. There are three kinds of schemata: hierarchical, linear and planar.
- Hierarchical refers to a nested parent-child relationship. Take, for instance, the pie chart article classified as a Graphs topic. Graphs might actually be a subset of a larger topic like "Quantitative Information" so there is a hierarchical relationship: "Quantitative Information” > "Graphs" > "Pie Chart Article"
- Linear metadata refers to metadata that is discrete, or one-dimensional, in that there are no subsets or supersets. The Dublin Core Metadata Element Set is one dimensional.
- Planar meta data is a kind of combination: Each element is discrete from all other elements, but classifications have two discrete elements, and hence are two-dimensional.
-
Granularity:
When creating a metadata taxonomy, it's important to consider the level of granularity, or detail. A good way to think about granularity is to consider how much content will fall under a specific metadata topic. If the metadata taxonomy is too broad, there will be too much content in each topic and it might be so varied that searchers can't readily pinpoint what they're looking for. If the taxonomy is too granular, needles can be pinpointed in the haystack but the cost of such granular tagging and of maintaining the taxonomy over time may be prohibitive.
-
Hypermapping:
When data is overlayed on graphical elements such as maps, it often requires a hypermapping schemata. These are geospatial elements that serve special views and account for applying real-world complexities like the curvature of the earth.
Metadata Creation
There are several important considerations when building a metadata taxonomy for a business. The first is to consider the scope of metadata requirements. Almost certainly, metadata will be required for web pages to influence how they are indexed and shared. Metadata is also used in image and video repositories, in content management systems and even in customer relationship management (CRM) systems.
The next step is to consider which specific metadata elements to use, for example, from among the 15 standard metadata elements that describe most digital content mentioned at the beginning of this article. More important than the number of tags associated with an item is that they are used consistently and comprehensively.
It's also important to decide the format for each of these elements and to use them consistently. For example, the "contributor" and "creator" elements, if used, could be presented as "last name, first name" or "first name last name." However, using both will reduce the metadata's effectiveness because searching on one or the other will only yield results for the exact match. Similarly, when using the "subject" element, it's important to tag everything that belongs to a subject with the same words. If some articles about cell phones are tagged as “mobile” and others are tagged as "cell phones," a searcher won't receive a full picture of results.
The "coverage" element, which refers to content topic, is important, too. It requires developing a taxonomy of the topics covered by a company's promotional information and product data. For example, a vendor of plumbing supplies will use a different vocabulary than a company that builds animal enclosures. Again, consistency is vital so that a search result contains all available information.
Examples of Metadata
The most common types of metadata on web pages are the title tag, description tag and image tag. Combinations of these tags are used in search engine results and on social media. More sophisticated content management systems may use the 15 tags in the Dublin Core Metadata Element Set, which describe digital assets.
But metadata is far from exclusive to the web. Take, for instance, a prospective sale being added to a CRM. A data entry professional will add specific data about the deal, and also associate it with an existing customer record and a specific salesperson. These extra bits of information are a form of metadata that add color to the sale. The CRM will also automatically capture some additional information, such as a timestamp for when the record was created and perhaps inventory data to add the estimated delivery of the product.
This means a manager could drill into a sales activity report for a particular week and see the data from many different angles. Which sales person added the most prospective sales? Which products are being sold and what additional inventory is required? Looking at the pipeline, what is the best estimate for revenue by the end of the quarter?
Conclusion
Metadata is data that describes, structures and administers different forms of content. On the web, it can influence how a search engine ranks a white paper and the way the information is displayed. This is why it's important to create compelling titles and description tags, and to include compelling images. On other platforms, such as content management systems, digital asset management systems and customer relationship management systems, metadata provides different ways that information and images can be searched, organized and displayed.
Metadata FAQs
What industries use metadata?
Any industry that relies on and/or produces content can benefit from using metadata. Properly tagged cases in a legal database, for example, can help lawyers find information that pertain to their cases at hand. Metadata is used in the music industry to manage music files and ensure copyright compliance. In the retail world, metadata will lead shoppers to the particular products they are searching for.
What are the benefits of metadata?
Metadata annotates data with additional information that helps the data be found and managed. Search engines use some of the metadata in search results. Social sites and collaboration programs like Messenger and Slack also display the metadata when a URL is shared.
What are some examples of metadata?
On the web, articles, for example, include three specific bits of metadata: the title, a summary or description of the article and an image. Modern digital images also include metadata about the resolution of the image, the image's location and even the kind of camera used to take the photo. Some licensed content might include metadata, indicating the rights conveyed with the license.
What are the three types of metadata?
There are three main types of metadata: descriptive, structural and administrative. Descriptive metadata describes the contents of a document. Structural metadata contains information about how the document is organized. Administrative metadata contains technical information about a document.
What is metadata and how is it used?
Metadata is information about data. It is often used to describe the contents of a web page. Search engines and social sites use metadata to display information about a published resource. Metadata is also integral to content management, digital asset management and even customer relationship management systems. For example, a digital asset management system can use a photograph's resolution meta tag to give users access to all high-resolution images.







