
Potential customers have sent sales queries; responses to a survey are flooding in; online reviews of the company's products have appeared on social media. These are just a few of the countless text-based business messages and documents that businesses deal with every day. How can a company quickly sort through all this text, identify the most important messages and get a sense of how its products are perceived in the market? Text mining is designed to help.
What Is Text Mining?
Text mining uses artificial intelligence (AI) techniques to automatically discover patterns, trends and other valuable information in text documents. It's a subset of data mining, which is the process of finding patterns in large volumes of data. Text mining focuses specifically on unstructured data in everyday documents, such as emails, text messages, survey responses, customer feedback, online reviews, support tickets, websites, books and articles. Manually scanning and classifying these documents can be extremely time-consuming, so automating text mining can save businesses considerable time and effort. Managers can then use the discoveries to make better informed decisions and quickly take action.
Text mining vs. text analytics
The term “text analytics” is sometimes used to describe a further analytical step after text mining. After text mining extracts qualitative information, such as consumer sentiment, text analytics provides more quantitative statistical analysis of that information. This analysis is often presented in visual form as graphs, charts or tables. For example, applying text analytics to customer service emails categorized as having a negative sentiment could generate a customer churn analysis chart indicating the percentage of customers that are complaining about product quality, delivery problems or technical support.
Key Takeaways
- Text mining uses natural language processing and artificial intelligence to uncover patterns and relationships in unstructured text.
- It enables businesses to automatically identify useful information in emails, social media posts, customer service tickets, chatbots and other text.
- Text mining can help businesses quickly discover and respond to manufacturing or delivery problems, anticipate competitive threats and provide more personalized customer service.
- Businesses use text mining for many functions, from HR to manufacturing, IT, marketing, sales and customer service.
Text Mining Explained
Text mining makes sense of a mass of unstructured text by categorizing each document by its main topic, intent and sentiment (positive, negative or neutral). It uses natural language processing (NLP) techniques to analyze unstructured text, followed by artificial intelligence (AI) techniques, such as machine learning, to categorize the documents. This process uncovers patterns and relationships that would otherwise be hidden in the text. Machine learning algorithms can also produce models that predict new patterns and behaviors.
Why Is Text Mining Important?
It's estimated that up to 80% of business data consists of unstructured information such as text. Text mining enables businesses to extract more valuable information from the unstructured text generated every day in email messages, social media posts, customer service tickets, chatbots and other sources. Without an automated process, it can be extremely time-consuming or even impossible to analyze all this information. Automatic processing of text documents can also produce more accurate and consistent information. Text mining can help businesses quickly discover and respond to problems in manufacturing or customer service, anticipate competitive threats and provide more personalized customer service.
How Is Text Mining Used in Business?
Text mining can be used by businesses in many industries. Within a single business, there may be multiple opportunities to use text mining to improve customer relations, reduce risk, tune manufacturing, analyze the competition and monitor employee satisfaction.
Customer relationship management:
Mining multiple sources of customer input — such as support tickets, online reviews, surveys, feedback and chatbots — helps a business get a better understanding of its customers' changing needs and intents. The business can use this understanding to deliver a more personalized customer experience and forge longer-lasting, more profitable relationships while mitigating customer attrition.
Manufacturing and product development:
Analysis of machine logs and maintenance tickets can pinpoint problems in the manufacturing process, as well as in the finished product.
Email filtering:
Email system providers mine incoming email to identify distinctive characteristics of spam and phishing messages, automatically deleting or quarantining messages before they are delivered to employees. This helps businesses minimize the risk of cyberattacks.
Competitive marketing analysis:
Mining the sentiment of competitor reviews in sources such as Yelp enables a business to assess the competition's strengths and weaknesses.
Human resources:
By analyzing the content of emails and other communications within the company, HR teams can gain insights into employee concerns and measure employee engagement.
How Does Text Mining Work?
Text mining software uses natural language processing (NLP) together with rule-based systems and machine learning to discover otherwise hidden relationships, patterns and sentiment in text documents.
First, the unstructured text is preprocessed using NLP. This preprocessing can include any of these steps:
-
Cleaning:
Removing small words (a, an, the) and correcting misspellings.
-
Stemming:
Reducing a word to its stem by removing prefixes and suffixes (“hire” is the stem for both “hiring” and “hired,” for example).
-
Tokenizing:
Dividing text into distinct words and phrases.
-
Tagging parts of speech:
Identifying the parts of speech within text, such as nouns, verbs and adjectives.
-
Parsing syntax:
Analyzing the structure of sentences and phrases to determine the role of different words. This identifies the subject, verb and object of a sentence, for example.
The data is then ready for machine learning models that identify the patterns and relationships in documents. Each machine learning model must first be trained by feeding it documents that have been manually tagged as belonging to a certain category or containing a specific sentiment. From the training inputs, the machine learning system creates a predictive model. New documents are then fed to the predictive model, which assigns the appropriate classification or identifies the sentiment of the document.
The chart below outlines the process. The text mining software first preprocesses a text document using NLP, then feeds it into the predictive model that was built using training data. The model assigns a category tag to the document. Based on the category, the document may be routed to an appropriate handler or to text analytics software. For example, if the system is analyzing emails that customers send to the company's customer service email address and the model assigns the tag “defective product,” the email could be forwarded to the quality assurance department to examine the problem. Text analytics software could also examine the tagged emails to determine the percentage of delivered products that are defective.
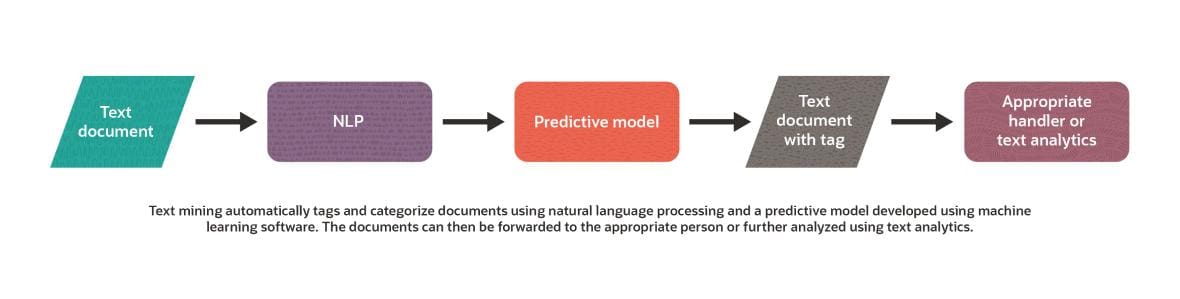
Text Mining Methods and Technology
Text mining focuses on gaining value from unstructured text, which accounts for the majority of business data today. Text mining tools use multiple basic and advanced methods to extract meaning from text.
Basic methods.
Basic text mining methods examine individual words or phrases within each document. These methods focus on analyzing:
- Word frequency is a technique that finds the words used most often within the document, recognizing synonyms. It is used to help identify the topic of the document.
- Collocation finds words that commonly appear together in a sequence or in the same sentence, such as “user interface.” This helps to identify their meaning. The sequences may consist of two words (such as “customer service”), which are called bigrams, or three words (“word of mouth,” “estimated delivery date”), which are called trigrams.
- Concordance determines the meaning of a word based on its context. After all, many words in the English language have multiple meanings. For example, does the word “pool” mean a swimming place, a game involving cues and billiard balls or a pile of contributed money?
Advanced methods:
Advanced text mining methods consider the context of the entire document or look for themes across multiple documents. They include:
-
Text classification, which identifies the theme, intent and sentiment of a document.
- Topic analysis identifies the main subject or theme of the document and perhaps also the minor themes.
- Sentiment analysis identifies the emotion, mood or feeling expressed in the document — whether it is positive, negative or neutral.
- Language detection classifies a document based on its natural language, such as English or Spanish.
- Intent detection identifies the purpose of the document. Is a customer trying to buy a product or get more information before buying?
-
Text extraction, also called information extraction, picks out important words or other data within the document.
- Keyword extraction finds the most common or most important words in the text, especially words that appear more frequently in this document than in similar documents.
- Named entity recognition extracts names of organizations, persons, products or places. This can be helpful in tracking social media conversations about the company's and competitors' products.
- Feature recognition extracts phrases that describe product features, such as color and size, or customer information, such as telephone numbers and addresses.
-
Multidocument analysis identifies trends and patterns across multiple documents.
- Clustering collects documents into groups based on common characteristics not found in other groups. For example, clustering could help to identify spam messages that use the same phrases.
- Co-occurrence identifies occurrences of the same terms in different documents. For example, finding the same product name together with the word “errors” in multiple documents could mean there are problems with a product.
- Trend analysis finds variations in topics or how those topics are treated in different time periods. Do new topics emerge while some topics disappear?
Benefits of Text Mining
Text mining can deliver many benefits, from enhancing the customer experience, to improving the creation and delivery of products, to reducing operational effort and cost. For example, text mining can:
-
Improve the customer experience:
One of the biggest benefits of text mining is to improve the customer experience. By automatically analyzing customer sentiment and identifying customer problems, text mining can help companies deliver more personalized, empathic service and respond faster to changing customer needs. IDC predicts that companies that use technology and data to excel in building empathy and safety into customer relationships will outperform their peers by 40%.
-
Improve product delivery:
By monitoring online product reviews, businesses can react quickly to negative product reviews to correct any defects. Monitoring reviews of competitors' products is also helpful to understand which features customers value. Mining trouble tickets may uncover shipping glitches, helping the company identify and address supply-chain problems.
-
Reduce cost and effort:
Automating cumbersome manual processes, such as categorizing and analyzing documents and messages, can save enormous amounts of time and effort, reducing operational cost and contributing to increased profitability. This can free employees to focus on higher-value tasks. Applying text mining can also provide more consistent and reliable results than manually sorting through vast numbers of text documents because it eliminates human error and variability.
Text Mining Challenges
Businesses that want to enjoy the benefits of text mining can face challenges related to the ever-growing volume of data and the need for specialized expertise in AI. However, technology improvements and training are helping to overcome these obstacles.
-
Growth of big data:
Many businesses face a growing deluge of data daily from sources such as product reviews, queries, emails, social media posts, support tickets and surveys. The sheer volume of data can present problems, especially when an organization is using an on-premises system with limited capacity to store and analyze information. Cloud-based applications which can scale processing horizontally and storage can provide the scalability needed to handle these large volumes of text.
-
Time required to train machine learning systems:
Training systems to extract information from text can be a lengthy process; IDC estimates that more than 50% of time is spent in preparing data for AI. Domain-specific tools that include built-in text mining capabilities, such as customized customer relationship management (CRM) mining software, can reduce this prep time.
-
Lack of domain and AI knowledge:
A current lack of skilled data science professionals is slowly being rectified as more universities offer data science programs.
Text Mining Applications & Examples
Many businesses already apply text mining to real-world applications. Typical examples include:
-
Public health:
Mining prescriptions and physicians' notes to uncover community health trends, such as the prevalence of diseases and changes in the drugs that are commonly prescribed.
-
Insurance:
Analyzing claim forms and detecting patterns that indicate fraud.
-
Retail:
Targeting advertising to highlight specific products, based on the terms in customer inquiries; training chatbots to automatically answer common customer product inquiries.
-
Finance:
Managing risk by automatically identifying trends contained in industry analyst reports.
-
Manufacturing:
Adjusting preventive maintenance schedules based on trouble tickets, helping companies save money by enabling them to prevent problems before they result in expensive breakdowns.
-
Law:
Accelerating and cutting the cost of the labor-intensive discovery process by searching through emails and documents and flagging relevant items for further review.
Future of Text Mining
Text mining techniques continue to become more sophisticated, thanks in part to research and development by major firms and universities. Trends include better sentiment classification, analysis and grouping of related text messages and categorization of the author and document. Sentiment analysis is moving beyond simply categorizing content as positive, negative or neutral to identify emotions such as disappointment, happiness, sadness, anger or confusion. Entire social media conversations, rather than individual posts, can also be analyzed to better identify themes and context.
Over time, text mining capabilities will increasingly be built into business applications. Trends in text mining tools include more domain-specific products focusing on areas such as customized customer relationship management (CRM), market research, healthcare and pharmaceutical research and survey analysis. These preprogrammed, pretrained tools allow managers to mine text without spending many hours preparing data for the machine learning system.
Conclusion
Text mining can help businesses extract value from the ever-growing flood of text-based sources, including email and social media. Companies can use text mining to improve many aspects of the business, including customer service, product development and manufacturing. As text mining becomes increasingly widespread, companies may find themselves under pressure to take advantage of the technology in order to maintain business growth and keep up with competitors.
Text Mining FAQs
What's the difference between text mining, text analysis and text analytics?
Text mining and text analysis refer to artificial intelligence (AI) techniques that automatically discover patterns and trends in text documents. Text analytics refers to quantitative analysis of these patterns and trends, typically for presentation in graphs and tables.
What is text mining in computer science?
Text mining uses algorithms developed in computer science, such as natural language processing (NLP) and machine learning. Over time, these algorithms are being incorporated into business tools and applications.
What is the difference between text mining and NLP?
Natural language processing (NLP) is one step in the broader text mining process. NLP techniques are used to prepare unstructured text for mining using machine learning algorithms.
What is text mining in big data?
Big data includes both structured and unstructured data. Text mining focuses on gaining value from unstructured text, which accounts for the majority of business data today. Unstructured text can be found in everyday documents, such as emails, text messages, survey responses, customer feedback, online reviews, support tickets, websites, books and articles. The techniques for mining unstructured text are different from the techniques for mining structured data found in databases.







